Objectives
The objective of this project is to build an intelligent, AI-powered invoice processing system that automates the extraction, validation, and management of financial data using state-of-the-art OCR and machine learning technologies. The system aims to reduce manual data entry, eliminate human errors, and significantly increase the efficiency of finance and accounting workflows across organizations.
A major goal is to develop a robust and scalable OCR pipeline that supports multilingual invoice processing, specifically English and Arabic documents. The pipeline integrates PaddleOCR, Nanonets OCR, and custom preprocessing algorithms to extract text, detect bounding boxes, and process diverse invoice layouts with high precision. Nanonets acts as a secondary OCR engine to cross-verify extracted fields, enhance accuracy, and strengthen reliability across varying formats.
The project also focuses on implementing a comprehensive backend architecture using Node.js and Express, responsible for orchestrating OCR requests, managing API workflows, performing data validation, and storing OCR output. MongoDB is used as the primary database for storing invoices, extracted fields, audit logs, and versioned updates. The system includes rule-based and AI-assisted validation methods—such as custom IOU-based bounding box comparison—to ensure the extracted fields maintain enterprise-level accuracy.
A modern, clean, and highly usable React.js frontend is developed to enable users to upload invoices, review extracted results, verify or correct fields, and monitor system performance. The interface supports bilingual interaction (Arabic and English), real-time updates, and an enterprise-grade user experience.
Overall, the objective is to produce a high-performance, scalable invoice automation solution that demonstrates the practical use of OCR, AI, and full-stack engineering to solve real-world financial automation challenges while ensuring accuracy, transparency, and operational efficiency.
Socio-Economic Benefit
The Invoice AI Automation System delivers significant socio-economic value by transforming how organizations manage their financial documentation. By automating invoice extraction, validation, and verification through advanced OCR technologies such as PaddleOCR and Nanonets, along with AI-driven processing, the system drastically reduces the time and workforce required for manual data entry. This leads to increased operational productivity, allowing employees to focus on higher-value tasks instead of repetitive manual work.
Economically, the system helps organizations cut costs associated with human errors, delayed processing, and inefficient bookkeeping. Accurate and automated data extraction reduces payment delays, improves cash-flow visibility, and minimizes financial discrepancies. Small and medium-sized enterprises especially benefit from affordable automation that was previously only accessible to large corporations.
By supporting multilingual invoices, including Arabic and English, the system promotes financial inclusivity in culturally diverse regions such as the Middle East. It empowers companies to adopt modern digital accounting workflows regardless of language barriers.
The system also contributes to job upskilling by enabling finance staff to work with AI-assisted tools, increasing their technological literacy and improving employability in the digital economy. Over time, organizations gain better transparency, faster audits, and stronger compliance with tax and financial regulations, supporting economic stability.
On a broader level, the automation of financial processes encourages digital transformation across industries, promoting innovation, competitiveness, and long-term economic growth. The project demonstrates how practical AI applications can streamline real-world operations, reduce inefficiency, and contribute to sustainable socio-economic development.
Methodologies
The system was developed using a structured, multi-phase methodology designed to achieve high accuracy, multilingual support, and scalable automation for invoice processing. The methodology integrates OCR technologies, intelligent field-extraction logic, and modern MERN-based software engineering.
1. Requirement Analysis
The process began by identifying key challenges in traditional invoice handling—manual data entry, errors, inconsistencies in formats, and the need for bilingual (Arabic/English) recognition. Core requirements included accurate field extraction, validation checks, duplicate detection, audit logs, and a user-friendly interface for reviewing results.
2. Technology Evaluation
A technical comparison was conducted between various OCR engines. PaddleOCR was selected as the primary extractor due to its efficiency and multilingual accuracy, while Nanonets OCR was added as a secondary model for cross-verification. Research also focused on preprocessing techniques and bounding-box-based validation using IOU (Intersection over Union).
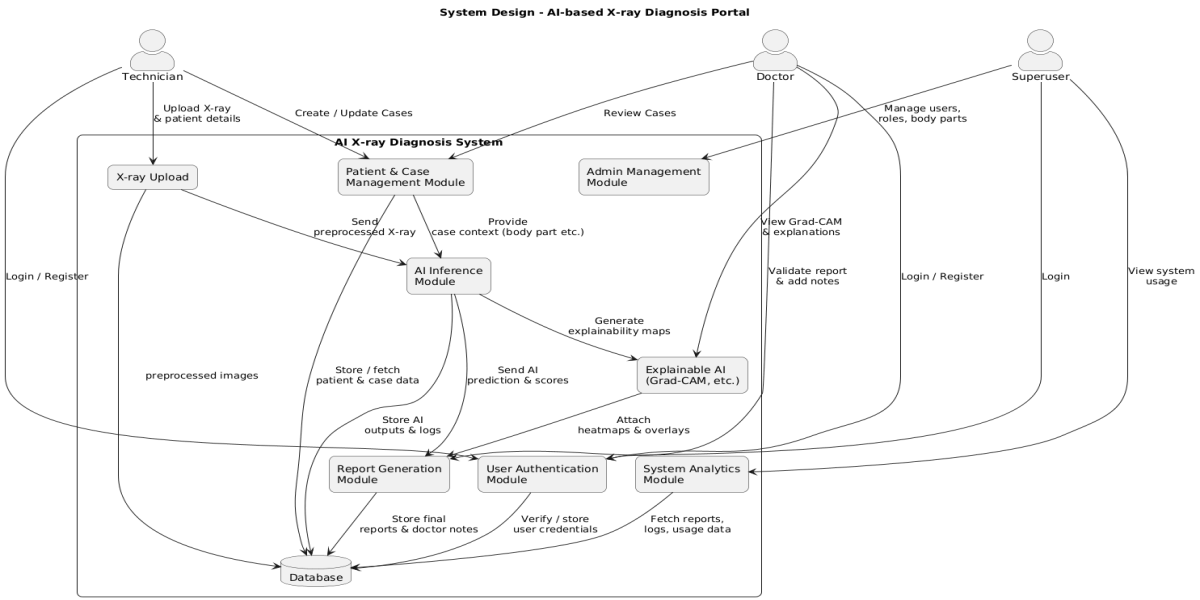
3. System Architecture Design
The overall architecture follows a modular MERN approach:
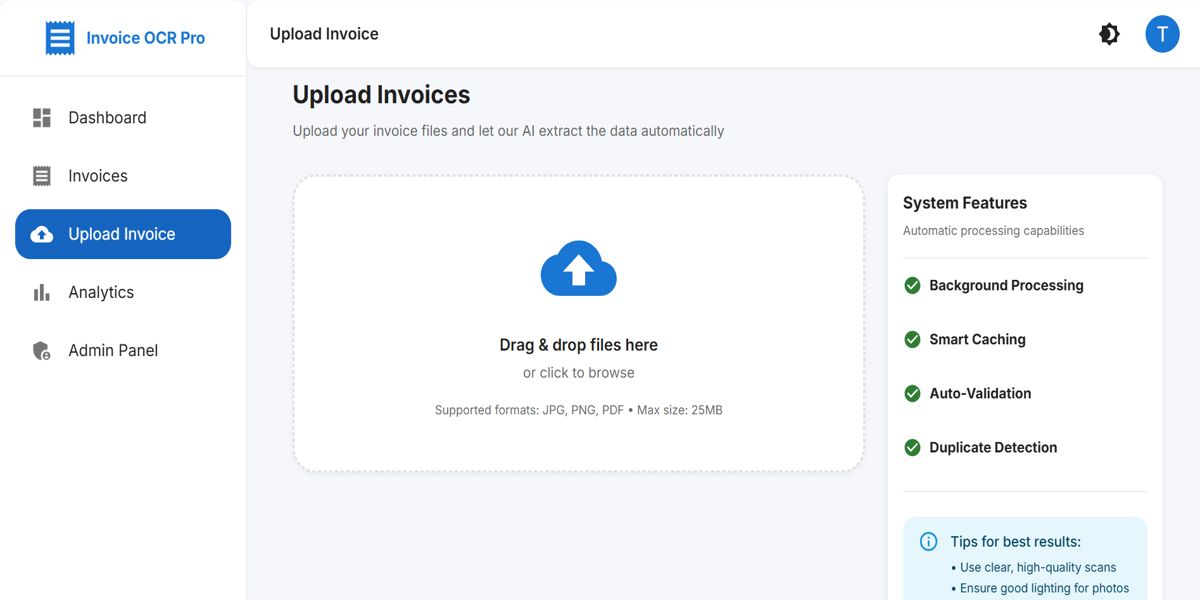
Frontend (React + Material UI): invoice upload, bilingual UI, extracted-field viewer, correction screen, history tracking, analytics.
Backend (Node.js + Express): OCR coordination, field extraction workflows, validation logic, caching, hashing for duplicate detection.
OCR Layer: PaddleOCR + Nanonets working together to improve accuracy.
Database (MongoDB): storing raw invoices, extracted fields, audit logs, and versioned updates.
4. OCR Pipeline & Field Extraction
Field extraction is the core methodology. The pipeline includes:
Preprocessing: noise removal, contrast adjustment, skew correction, contour detection to improve OCR quality.
Primary Extraction: PaddleOCR identifies text segments and generates bounding boxes.
Cross-Verification: Nanonets OCR reconfirms key values such as invoice number, date, vendor, totals, and line-items.
Field Mapping: Text segments are grouped and matched to expected invoice fields using positional logic and keyword heuristics.
Bounding-Box Validation: IOU-based algorithms verify that extracted fields fall within correct regions, improving accuracy on mixed-layout invoices.
Structured Output: Clean, standardized JSON of all extracted fields is produced for storage and review.
5. Backend Logic & API Implementation
The backend handles request management, OCR processing, validation rules, and storing extracted fields. Duplicate invoice detection is performed using hashing, while caching reduces repeated OCR costs. APIs follow REST standards for easy integration with dashboards and external systems.
6. Frontend Development
A clean, enterprise-style interface was created in React and Material-UI. Users can upload invoices, view extracted fields instantly, correct values, switch languages, and review previous invoices. Special focus was placed on clarity during field-correction
Outcome
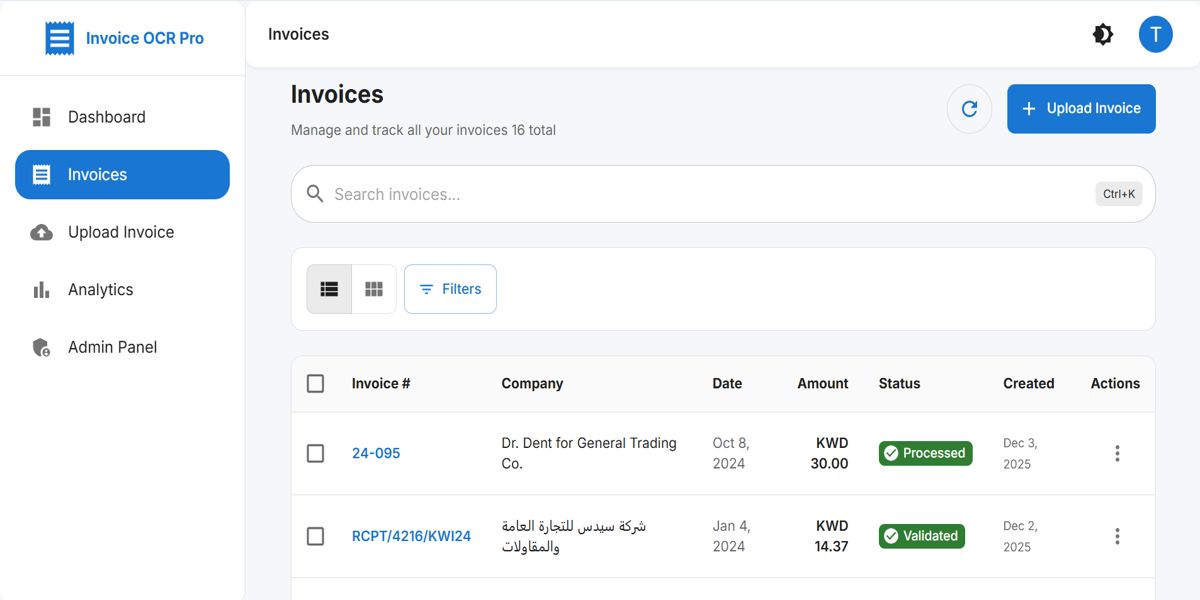
The project successfully produced a fully functional, multilingual Invoice Processing Automation System capable of accurately extracting structured data from invoices using PaddleOCR, Nanonets, and custom IOU-based validation. The system achieved strong results in field extraction accuracy, reliably identifying key elements such as invoice numbers, dates, totals, VAT amounts, vendor information, and line-items across both Arabic and English documents.
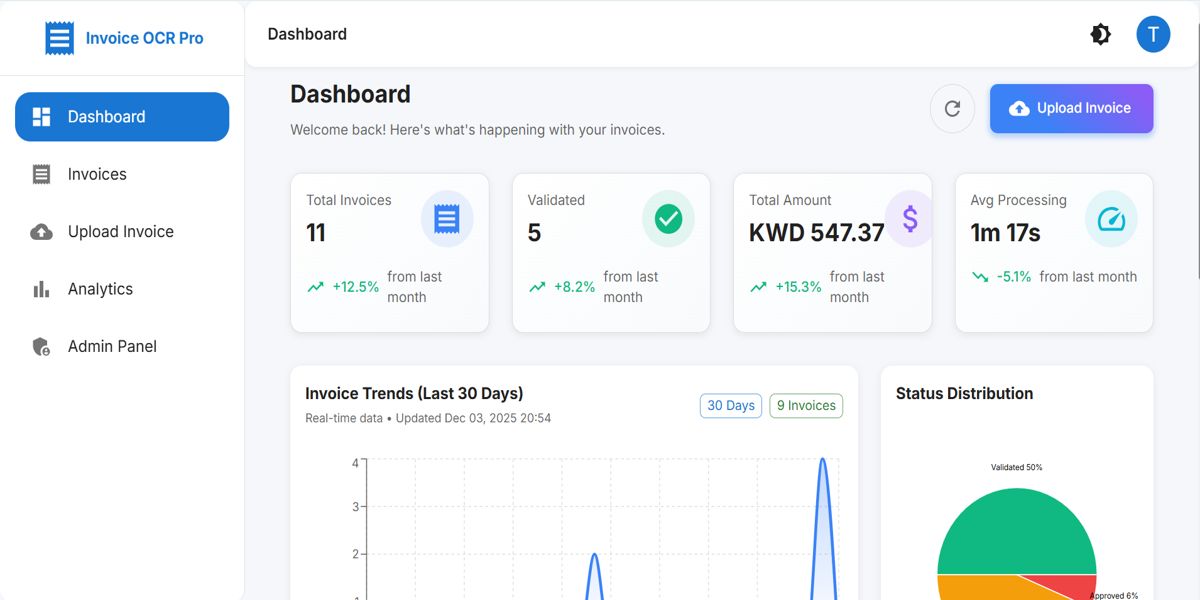
The MERN-based application provides a clean interface for uploading invoices, reviewing extracted fields, correcting values, and accessing invoice history. Backend modules effectively manage preprocessing, OCR orchestration, duplicate detection, schema validation, and secure data storage.
Testing demonstrated significant reductions in manual workload and processing time, with most invoices being processed in seconds instead of minutes. Accuracy improved through cross-verification and bounding-box validation, making the system more dependable than single-engine OCR solutions.
Overall, the project delivered a stable, scalable, and practical automation tool that enhances efficiency, reduces human error, and supports real-world invoice workflows, laying the foundation for integration with enterprise financial systems.