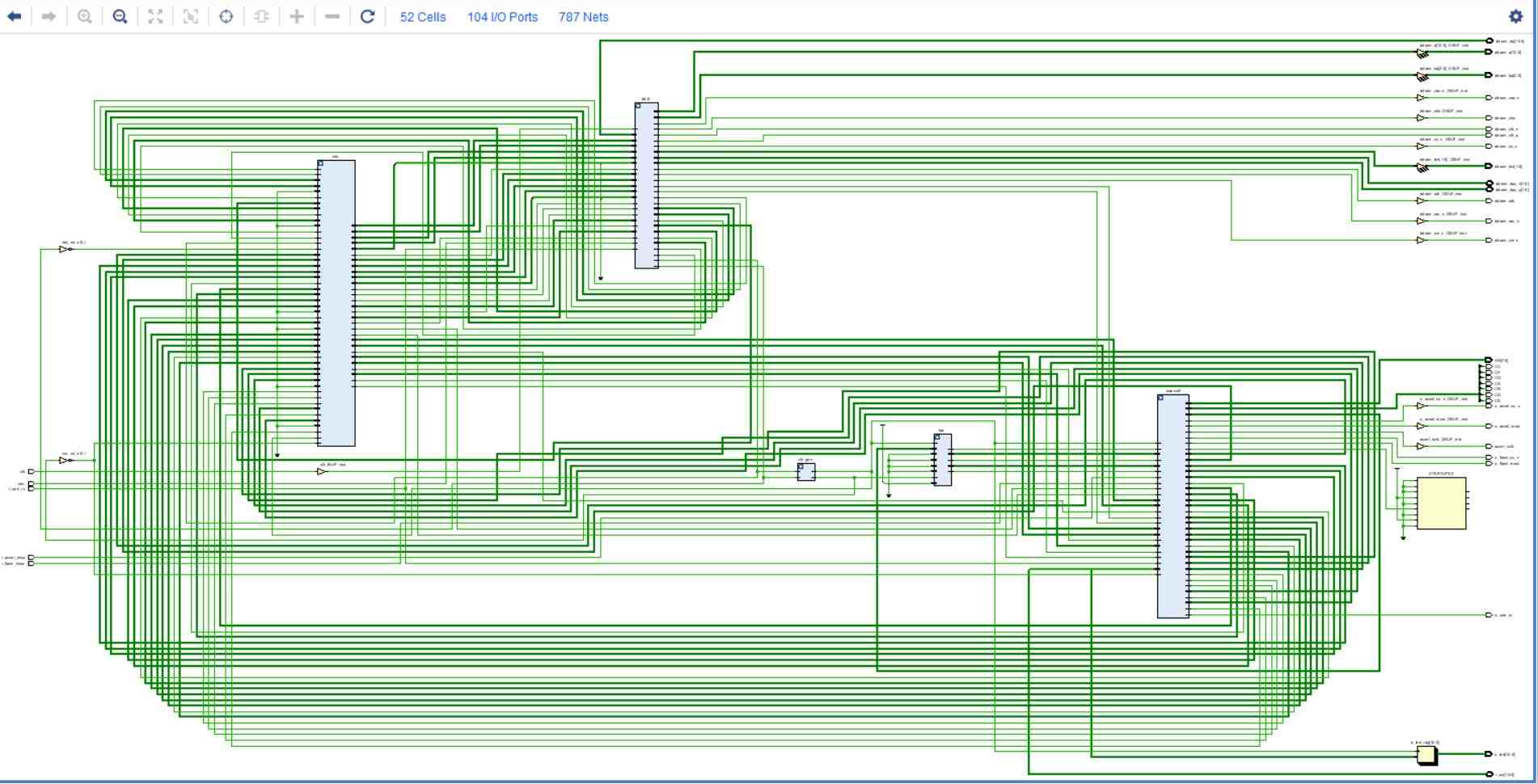
This project implements a highly configurable Multiply-Accumulate (MAC) accelerator tightly coupled to the open-source SweRV EH1 RISC-V core via a memory-mapped AXI4-Full interface. The unit supports 2×2, 4×4, 8×8 and 16×16 multiply modes with on-the-fly selection of accumulate and clear operations. When mapped to Xilinx FPGAs, it delivers over 4× speed-up on MAC-heavy kernels while occupying minimal area. This work showcases an efficient hardware-software co-design for embedded signal-processing and machine-learning applications on RISC-V.
Objectives
The objective of this project was to develop and integrate a flexible, high-throughput Multiply-Accumulate (MAC) accelerator into the open-source SweRV EH1 RISC-V core—delivering multi-precision (2×2 to 16×16) MAC operations selectable at runtime—using a memory-mapped AXI4-Full interface, to achieve significant speed-ups on signal-processing and machine-learning workloads with minimal area and software overhead.
Socio-Economic Benefit
Cost Savings: Open-source RISC-V and compact FPGA MAC lower hardware licensing and BOM costs.
Energy Efficiency: 4× faster MACs slash power vs. CPU-only, reducing operational bills.
Democratization: Enables startups, academia, and emerging markets to leverage high-performance ML without hefty R&D budgets.
Edge & IoT Enablement: Small footprint, runtime-configurable accelerator ideal for battery-powered, low-cost devices.
Methodologies
Requirements & Architecture
• Defined MAC use-cases (precision modes, control interface)
• Mapped accelerator onto AXI4-Full slave model for SweRV EH1 integration
RTL Design & Verification
• Wrote parameterizable Verilog for multi-precision MAC (2×2–16×16 + accumulate/clear)
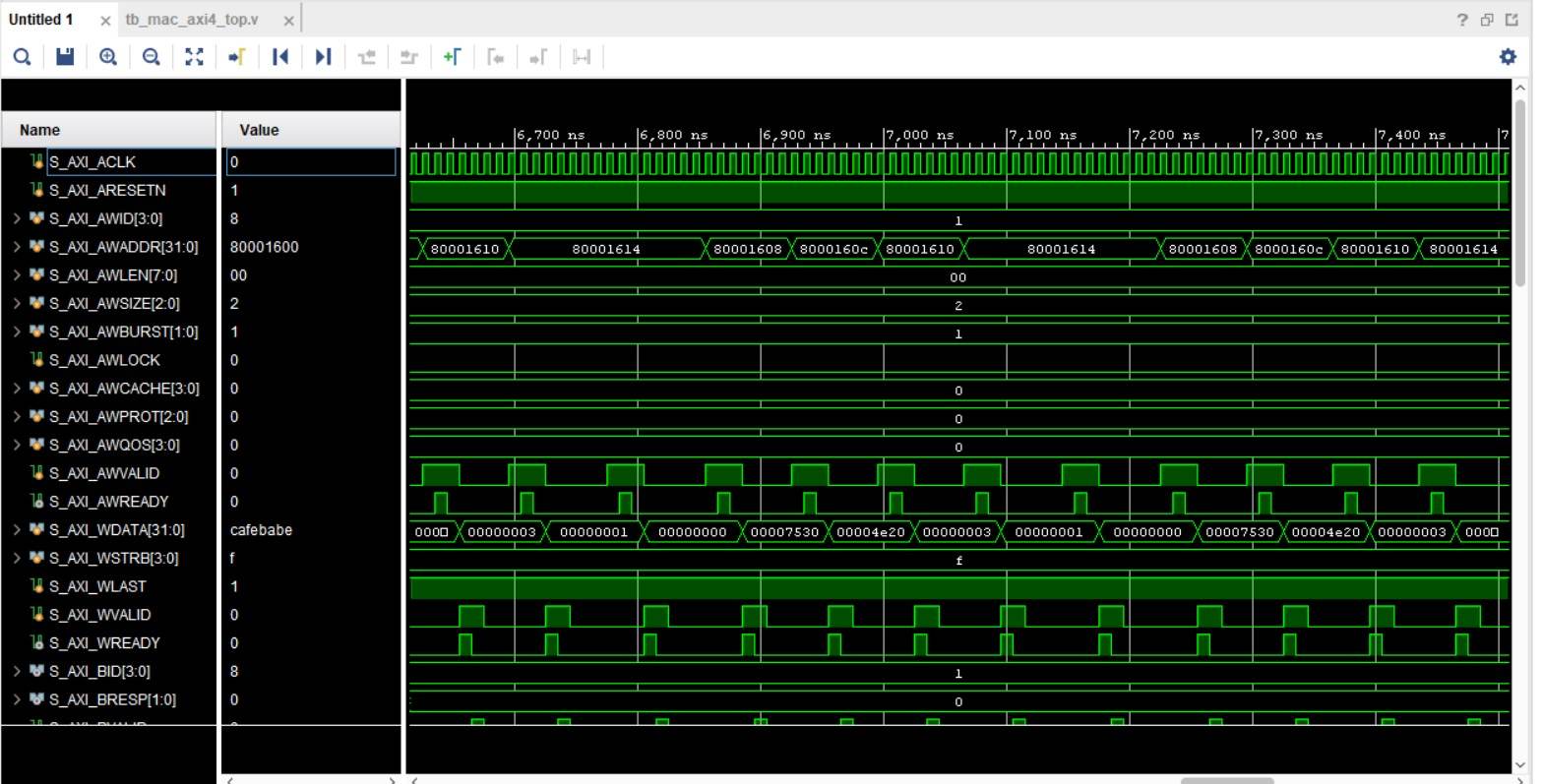
• Ran functional simulation (ModelSim/Vivado) with directed and randomized test-vectors
Integration & System Verification
• Wrapped MAC as an AXI4-Full slave and regenerated PULP-Platform interconnect
• Created a Vivado SoC project embedding SweRV EH1 + MAC + DRAM controller
• Exercised end-to-end MAC calls via C/C++ drivers on the bitstream
FPGA Prototyping & Benchmarking
• Synthesized on Nexys A7-100T, generated bitstream, and deployed via PlatformIO
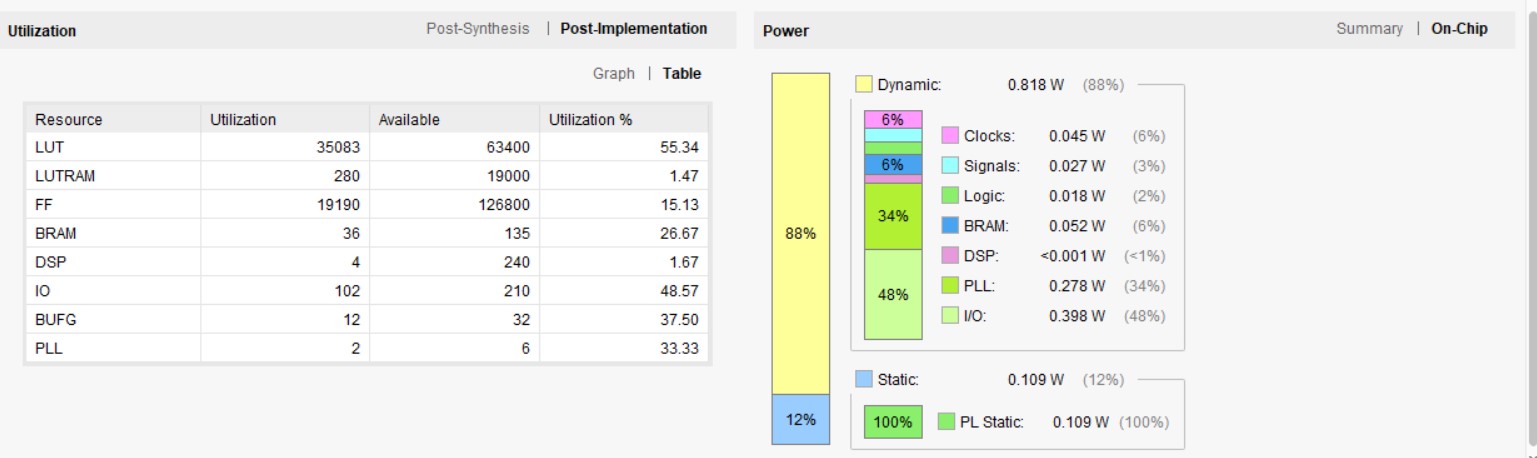
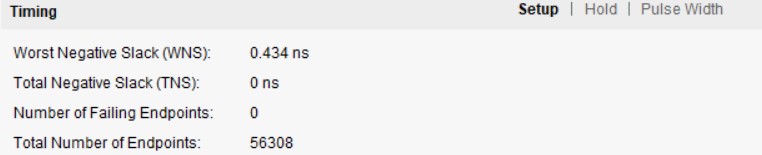
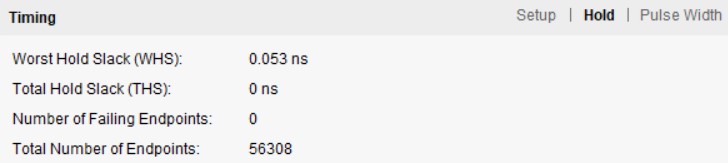
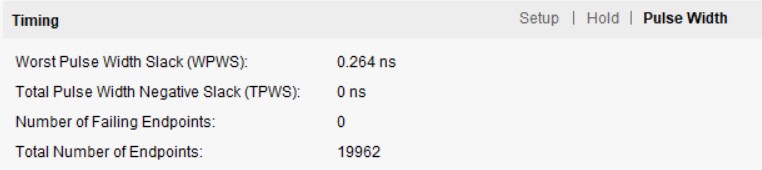
• Measured throughput and area, demonstrating 4× kernel speed-up with minimal LUT/FF usage
Outcome
- Fully Functional Multi-Mode MAC Accelerator.
- Seamless RISC-V Integration
- FPGA Implementation
- Performance Gain
- Verification & Validation
- Enables low-cost FPGA acceleration for edge AI and signal processing